
Minesweeper bench
TLDR:
Minesweeper seems to make all LLMs go through hell. They fail consistently through it. I think this is because its out of their training data.Introduction
I realized that I wanted to do a benchmark right after seeing the ARC side quest. In this benchmark they made LLMs play snake! Its such a cool concept so I wanted to tag along.

My first instinct was to do something similar like pong. I implemented it but felt that it was not something novel. So I decided to instead do something different. I decided to do another game that required reasoning.
I decided on a game from my childhood, minesweeper. I realized that you have to handle a lot of uncertainty. At first, minesweeper feels like intuition, but it can be a lot of reasoning. But, how do you play it?
The rules of the game
You have a board of NxN size where each tile can have three different states.
- Empty
- Bomb
- Number
In a fresh board, all the tiles hide their contents. You have two actions, you can either reveal a tile or flag it. Flagging a tile only helps you to know where you think there is a bomb. Revealing the tile has three possible consequences:
- you reveal a bomb and you loose,
- reveal a numbered tile
- reveal an empty tile.
If you reveal an empty space, the game reveals all neighboring tiles until it reaches a number. Numbered tiles tell you exactly how many bombs are surrounding the specific tile.
The challenge comes from having partial information. For example, if you see a hidden tile completely surrounded by the number “1”, that hidden tile must be a bomb.
The game ends when there are no more moves. But I decided on two possible win states: Either you don’t have any move left or you flag all the bombs in the board. This is easier to win than the original game.
If you didn’t get the explanation, you can play with it below!
Why this benchmark?
Current LLMs are starting to have a lot more reasoning capabilities so I wanted to test them.
This benchmark tests three different things:
- Probabilistic and Deterministic Reasoning: How are these models capable of dealing with uncertainty? Seeing models struggle helps us understand them more. They stumble and go in loops.
- Error Correction: They make mistakes, but are they capable of realizing them in time?
- Pattern Recognition: Minesweeper has a lot of patterns. Some of them are likely etched in the memory of these models, but, can we view some of them? And, are they helpful?
Methodology
I decided to start with an easy version of the game. So I googled minesweeper and Google has implemented a 10x8 board with 10 bombs as their easy version. In that same spirit, I decided to do a text mode mine game where the models get a 10 by 10 grid with 10 bombs8. There is a 10% chance of the first click being a bomb1, so I decided to let each model play 50 games. There is also a possibility of LLMs having a hard time or getting stuck on decisions, so I decided on a 50 turn timeout 2. Sometimes models are annoying and don’t follow the prompt that you give them. So I designated a category for the parsing errors.
In total, each model gets to have 50 tries and 50 turns to solve the board game3.
For the proprietary reasoning models: o1,
o1-mini and claude-thinking I only
used 4096 thinking tokens. This is because I didn’t want to
spend a ton in tokens. As for the open source reasoning models,
they got the maximum amount the providers were letting me
because they are cheaper.
I made a final choice about the models. They cannot see their past moves. This is because they should be able to solve the board’s current state on their own. I was hoping for the models to be capable of self-correcting on their own based on the current board.
The prompt for the models looks like the following:
You are playing a game of Minesweeper. Here is the current state:
BOARD STATE:
0 1 2 3 4 5 6 7 8 9
0 . . . . . . . . . .
1 . . . . . . . . . .
2 . . . . . . . . . .
3 . . . . . . . . . .
4 . . . . . . . . . .
5 . . . . . . . . . .
6 . . . . . . . . . .
7 . . . . . . . . . .
8 . . . . . . . . . .
9 . . . . . . . . . .
GAME INFO:
- Board size: 10x10
- Flags remaining: 10
- Bombs: 10
BOARD LEGEND:
- _ : Empty revealed space
- . : Unexplored space
- F : Flagged space
- * : Revealed bomb (game over)
- 1-8: Number indicating adjacent bombs
COORDINATE SYSTEM:
The board uses a coordinate system where:
- x represents the ROW number (vertical position, starting from 0 at the top)
- y represents the COLUMN number (horizontal position, starting from 0 at the left)
For example:
- Position (0,0) is always the top-left corner
- Position (board_size-1, 0) is the bottom-left corner
- Position (0, board_size-1) is the top-right corner
- Position (2,3) means: row 2 from top (third row), column 3 from left (fourth column)
NOTE: All coordinates are 0-indexed and must be less than the board size
RULES:
1. The goal is to reveal all safe squares or correctly flag all bombs
2. Numbers show how many bombs are in the adjacent 8 squares
3. You can either reveal a square or place/remove a flag
4. To remove a flag, make a move with flag=true on an already flagged square
5. Game ends if you reveal a bomb
CRITICAL FLAG PLACEMENT RULES:
1. Each number indicates EXACTLY how many bombs are adjacent - no more, no less
2. If a numbered tile shows '1', but already has an adjacent flag, there cannot be another bomb next to it
3. If a numbered tile shows '2' with only one adjacent flag, there MUST be another bomb adjacent
4. Before placing a new flag, verify that it doesn't conflict with the numbers you can see
5. If you see a potential conflict between a flag and revealed numbers, consider removing the flag
ANALYSIS STEPS:
1. First, check all revealed numbers against existing flags
2. Look for obvious conflicts (e.g., a '1' with two adjacent flags)
3. Consider the remaining number of flags vs bombs
4. Only then decide whether to place a new flag or reveal a tile
Provide your next move in this format:
EXPLANATION: (briefly explain your move)
MOVE: x,y,flag
where:
- x,y are coordinates (0-indexed)
- flag is true/false (true = place flag, false = reveal tile)Results
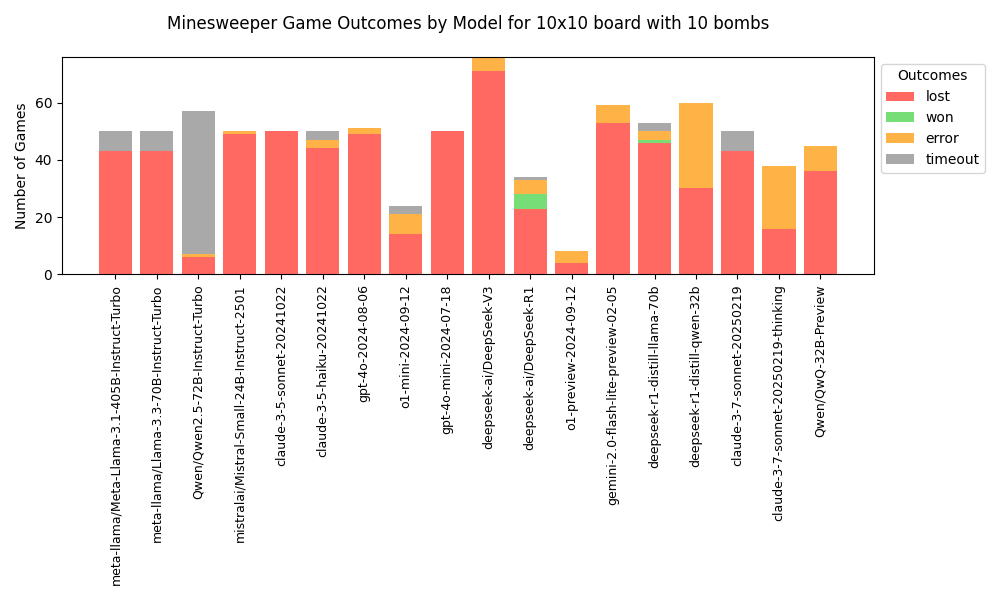
After running a total of 18 models through this. It seems that
only two models won, and only a single one was capable of
passing the benchmark more than once. The winner here was
DeepSeek-R1. But why?
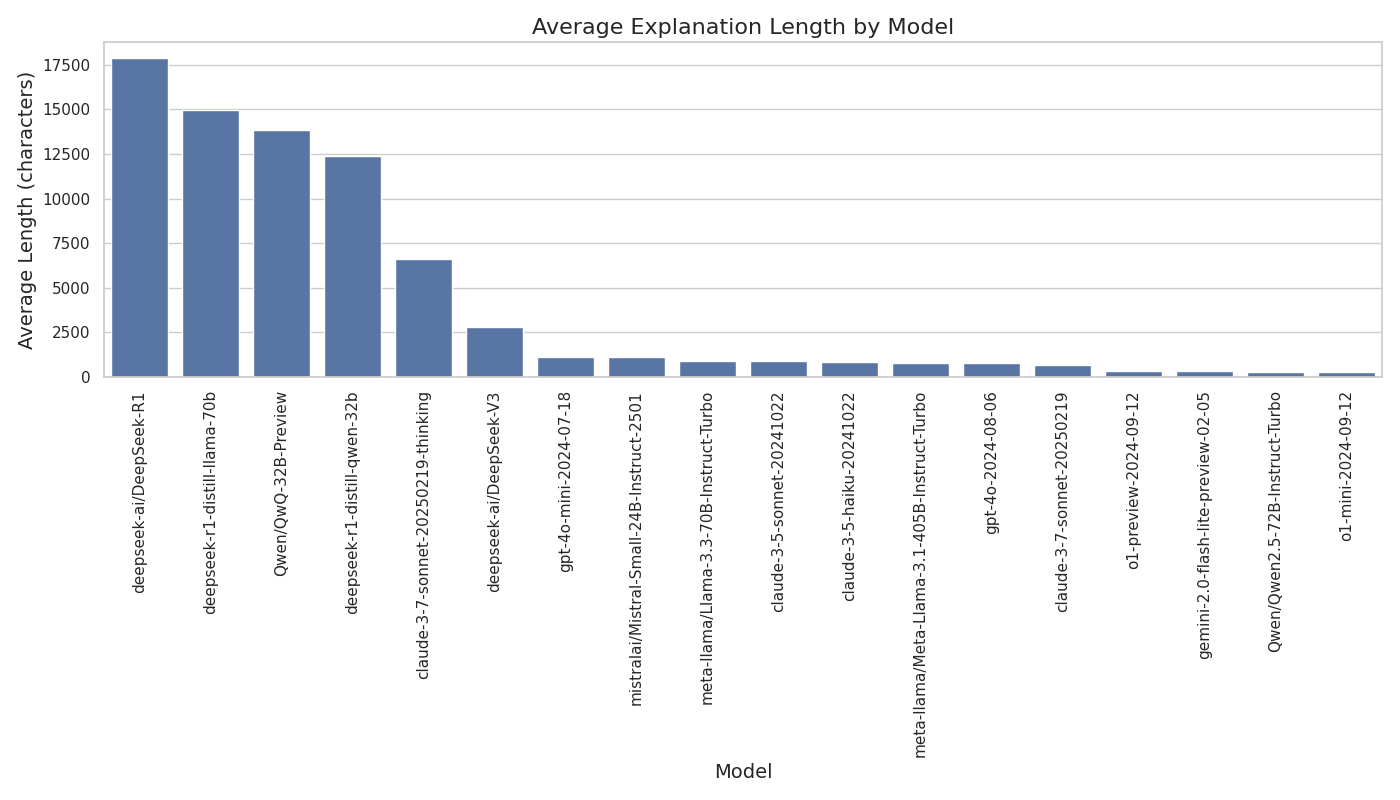
The reason why DeepSeek-R1 was winning is because it was the model that had the most amount of time to think things through. There is a reason why the only other model capable of solving this was the Llama distill from DeepSeek. But even then, the models are not capable of solving this benchmark. They have a failure rate that in my eyes is a little bit abysmal. Even then, visualizing how different models interacted with the board is pretty interesting.
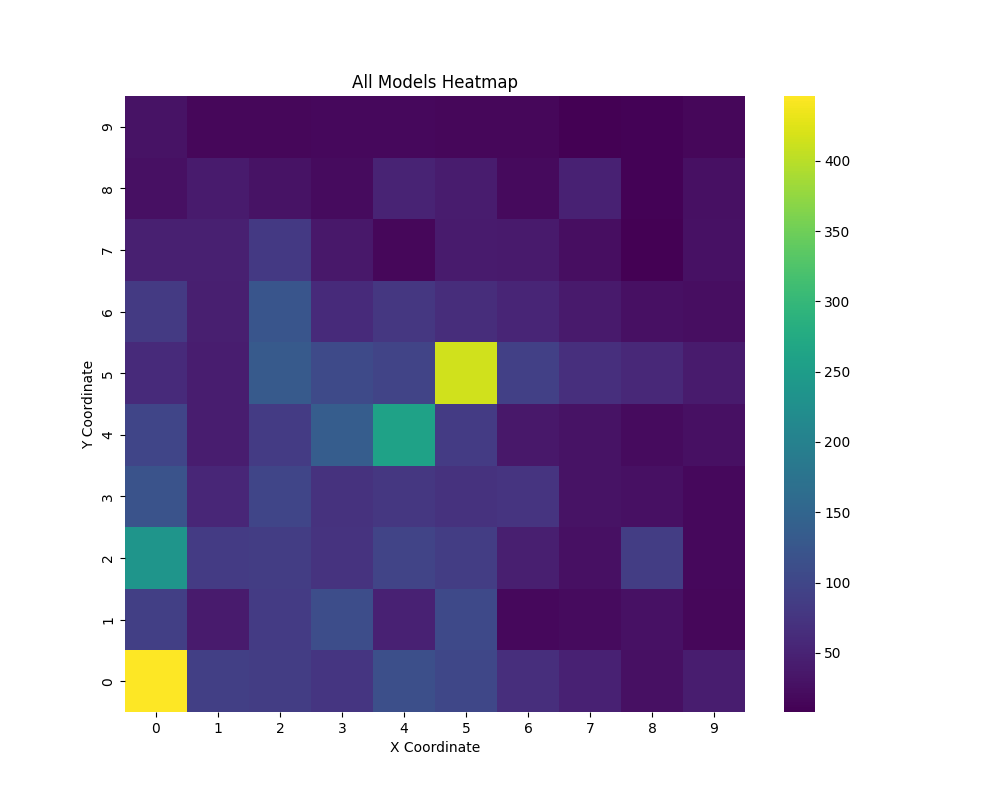
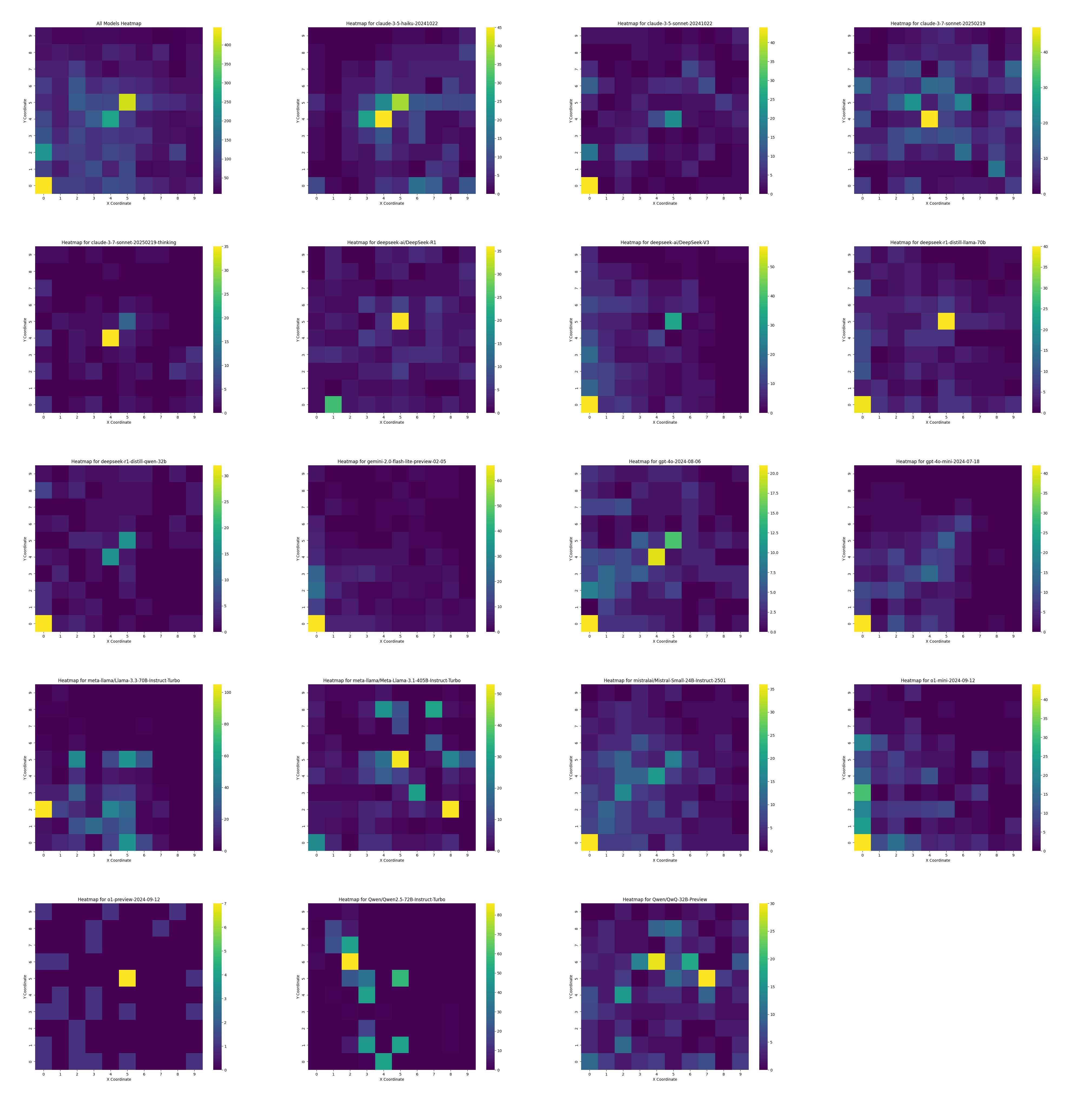
The distribution of coordinates from where the models are
clicking on the board. Here you can see a pattern that some
models love clicking the center of the board4
or the corner (0,0).
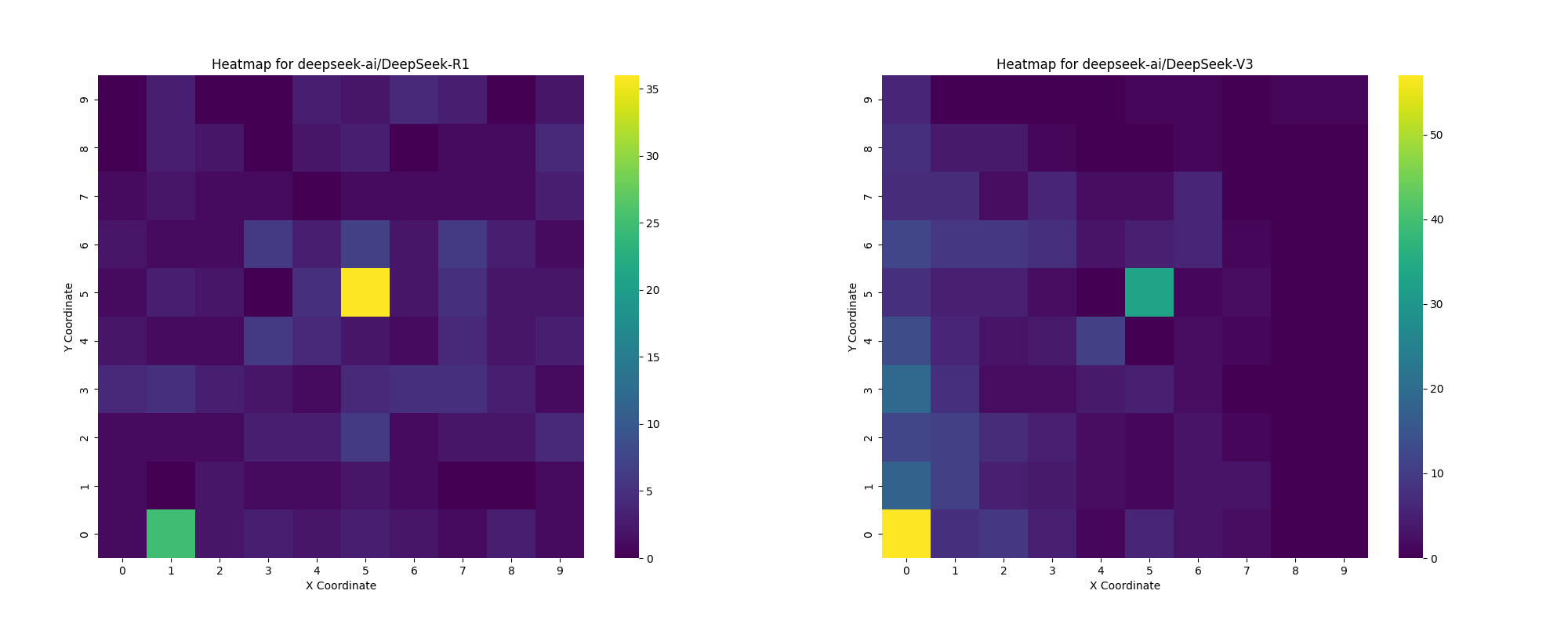
Each model had a different distribution of clicks. Even though DeepSeek-R1 and DeepSeek-V3 have the exact same base, their histograms don’t look similar. For R1 you can see the first move to be almost always the same but it clicks through the entire screen. Whilst V3 is only clicking for some reason half of the possible dashboard. It seems that it has a bias to do that.
Another example of this is Claude-3.5 and Claude-3.7:
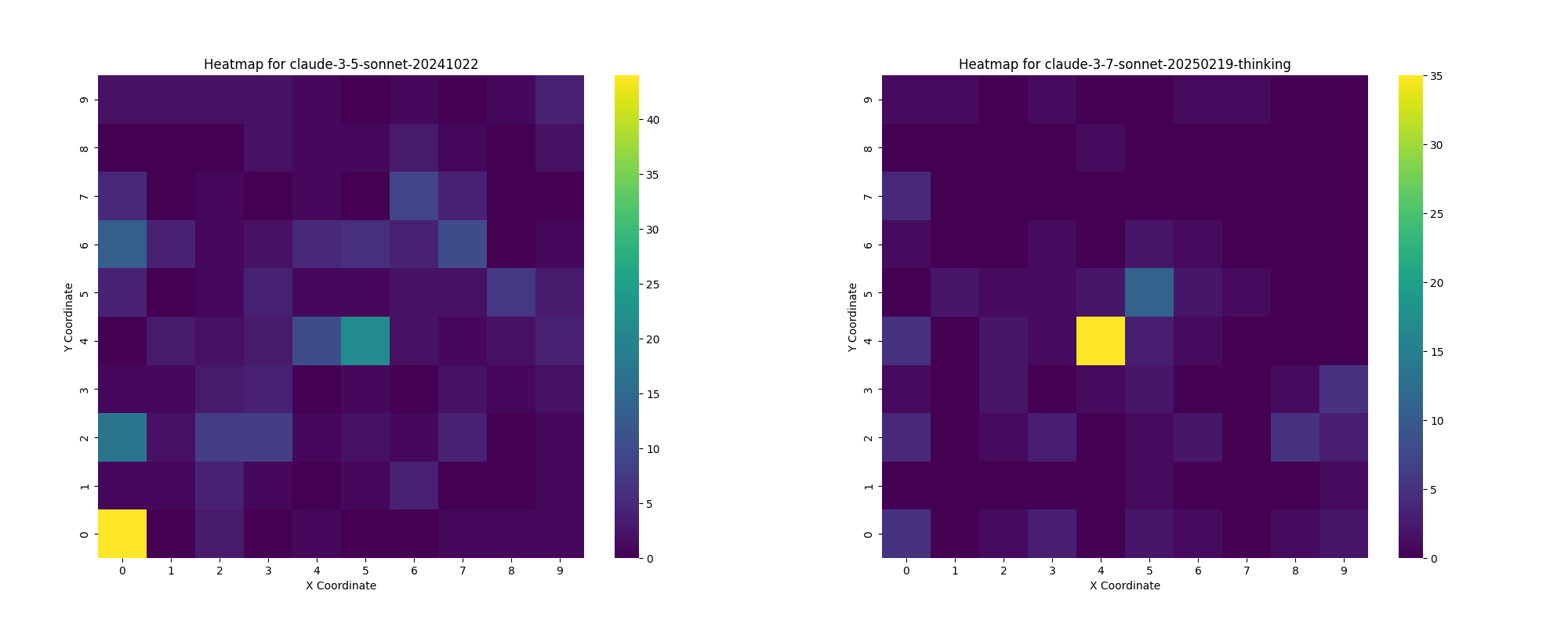
Even in finetunes you can see this results like in the
deepseek-r1-distill-llama-70b vs the original model
meta-llama_Llama-3.3-70B-Instruct-Turbo:
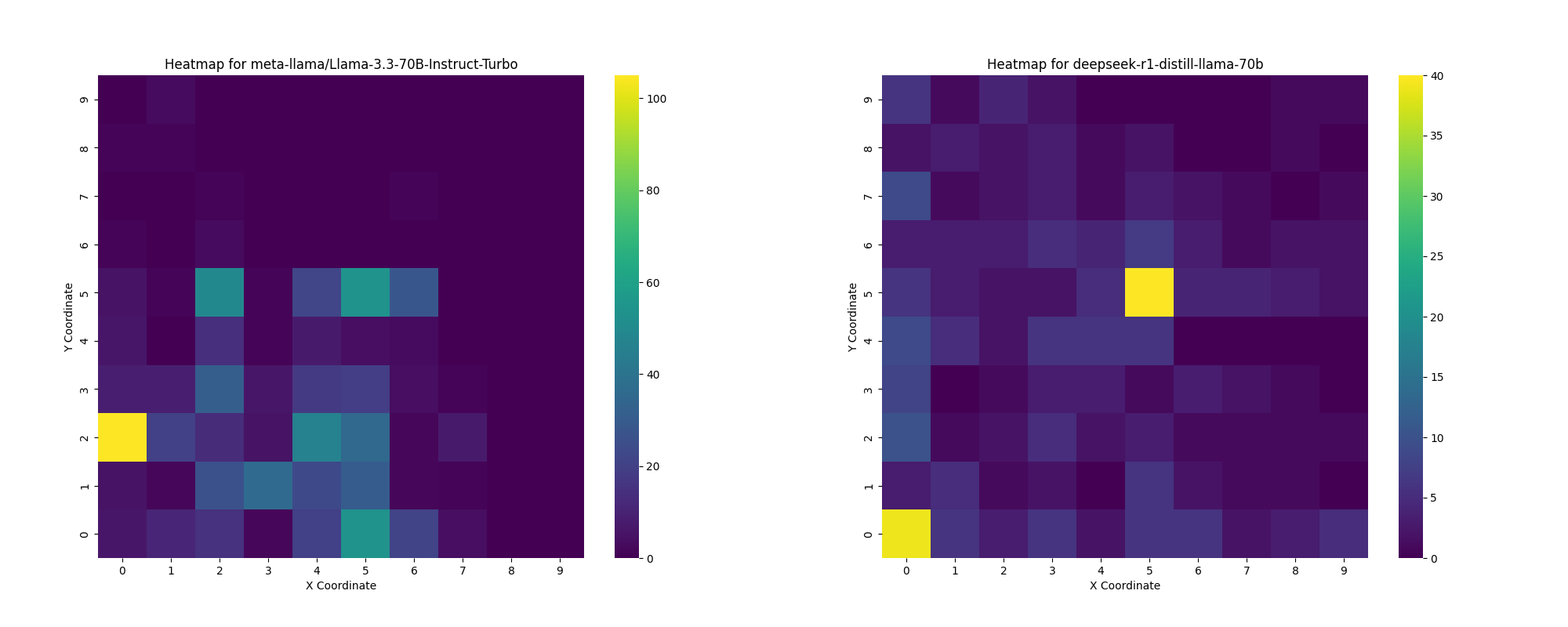
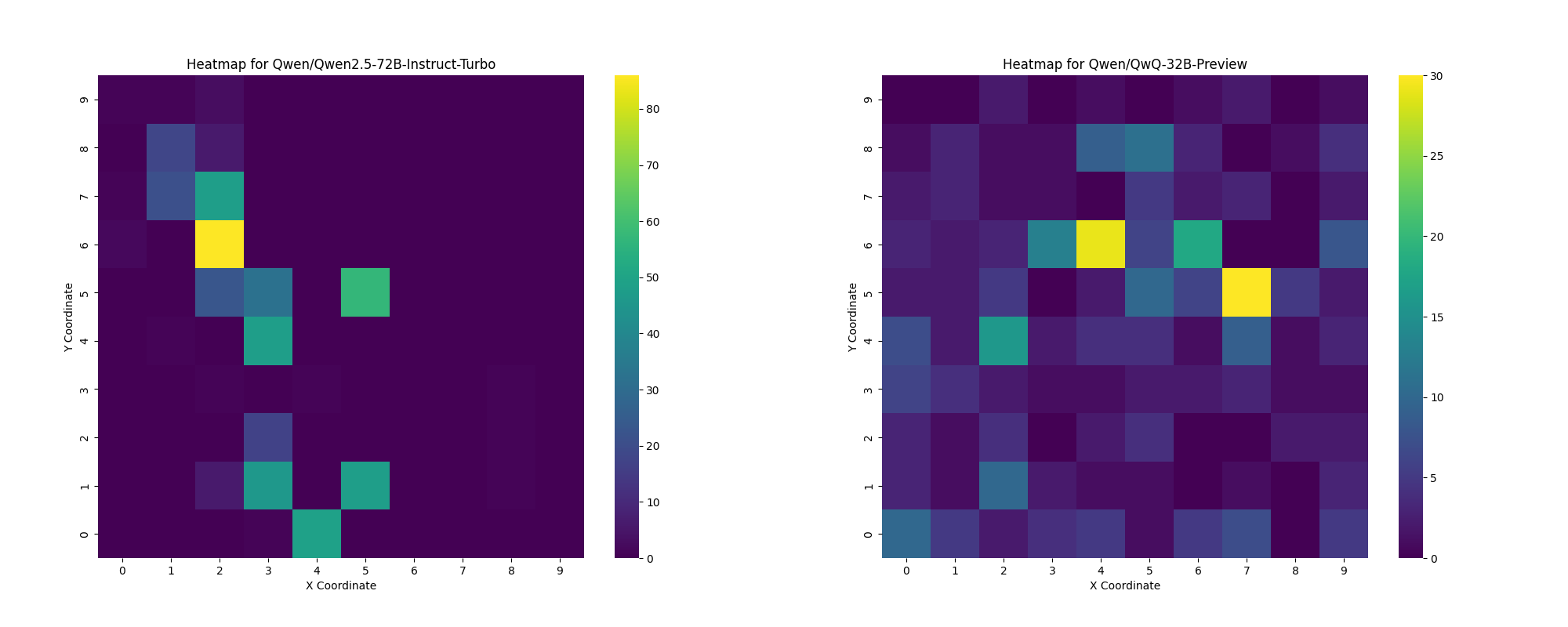
Also, there are some models that are incapable of going outside
their tiny box, this was the worst for
Qwen-2.5-72B-Instruct-Turbo5. But the thinking model from the Qwen family had a better
distribution.
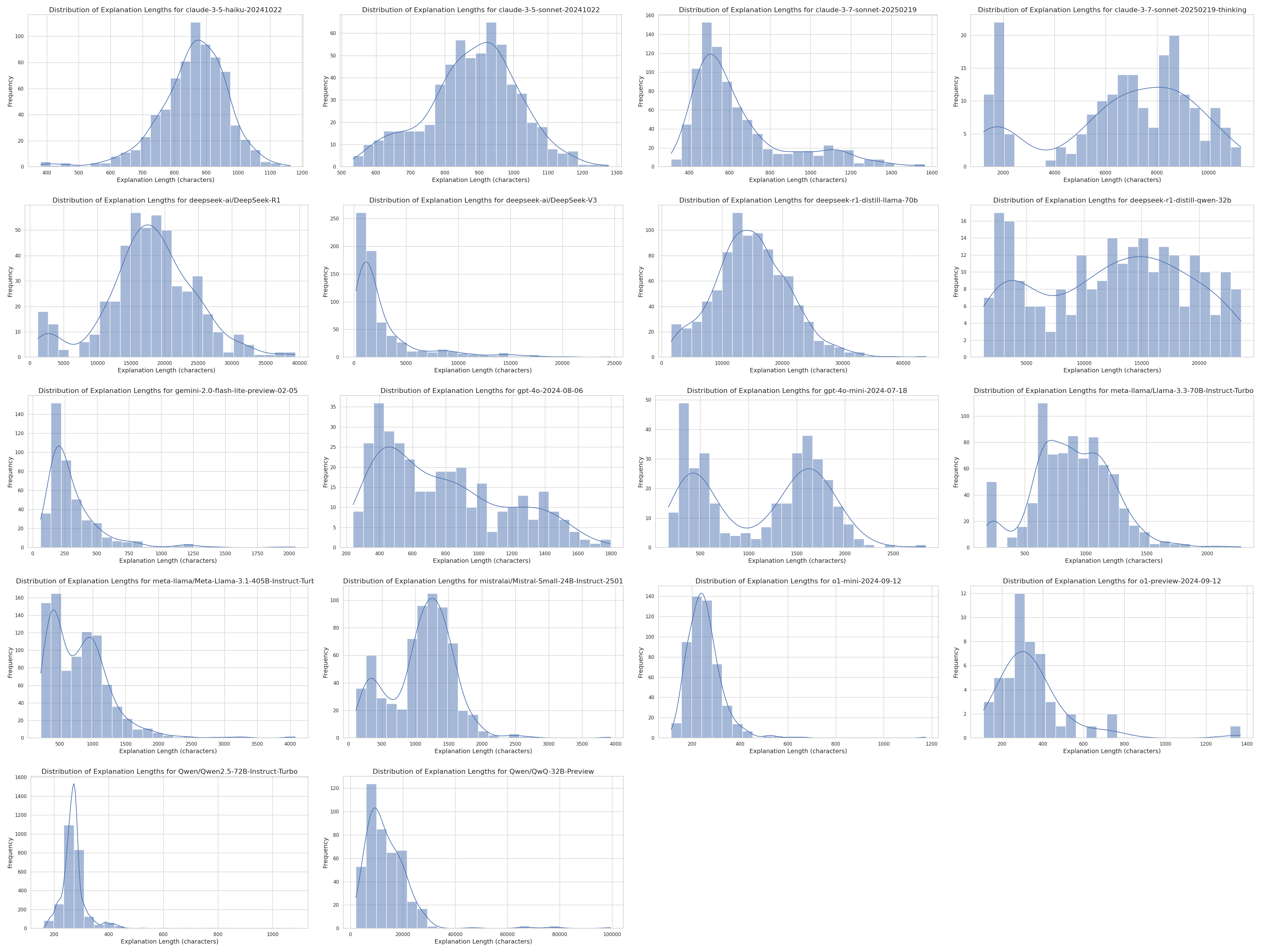
A last thing that is interesting to see is the output length distribution for each model. I was expecting to see a normal distribution but there were some surprises in here.
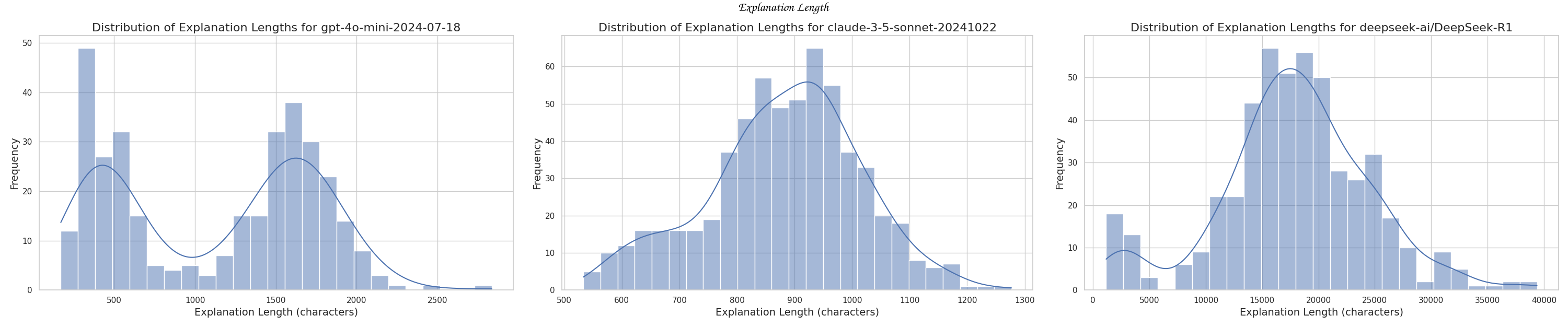
Some models had bimodal distributions like
gpt-4o-mini, others had a more normal distribution
like claude-3.5 or R1.
Future Predictions
Some predictions for fun:
-
Future large language models are going to be solving this game in the following 3 to 6 months.
-
If this gets some traction this will get solved in like a week.
Conclusion
It’s fun to see models have failure points, it helps us understand them better. This benchmark is not perfect. But, it gets to paint another picture of what current LLM big talk is saying right now. These models are great, but they still fail at what should be something simple to do.
As further work, it would be interesting to do a followup with a prompt that has all the patterns to see if the models do better.
I had a lot of fun doing this, I was not expecting this to be the first result of trying to develop a benchmark6. If you liked this article and would like to view the code, you can, the code is in github and if you want the results, those are at in the minesweeper_games directory.
I also have added a tiny visualizer with five different examples for how the models did.
Examples
Example playthroughs from the models:
Further reading / Cool links
- ARC Foundation Snake SideQuest Blogpost
- Minesweeper patterns
- Minesweeper research papers
- Minesweeper from Google
Appendix: Cool little graphics
These are the graphs for each model for either the heatmap or the text length.
-
100 tiles and 10 bombs equals the following equation: n_bombs/n_tiles = 10/100 = 10%.↩︎
-
50 turns seemed like a good breaking point and being absolutely sure that the model is just going in circles. You literally would click on half of the board for this to happen if you are human.↩︎
-
I literally don’t have all of the money in the world, sorry for no budget :(. So I just tried a couple of runs. If you are an interested person from a big lab, I would love to run the benchmark!↩︎
-
Non-zero indexing, tragic for the common LLM.↩︎
-
What a mouthful. Also, I think that if I misconfigured the model, I can't find the error. Every other model works so it must be some particularity of it.↩︎
-
Well I guess second because the first one was Pong.↩︎
-
I realized that Claude 3.7 was getting a bunch of errors from the way I was parsing the output data, so ignore the error part from this specific model.↩︎
-
There are a lot of games even in a 10x10 board with 10 bombs. It's a combination problem where we're selecting 10 positions from 100 possible positions: 100! / 10!90! = 17.3 trillion possible games. ↩︎